
Le nouveau modèle de DeepSeek réduit les coûts d'inférence de l'IA
DeepSeek vient de sortir quelque chose d'intéressant : un nouveau modèle expérimental, le V3.2-exp, qui, selon eux, pourrait sérieusement réduire les coûts d'inférence. Je veux dire, qui ne veut pas économiser de l'argent, n'est-ce pas ? Surtout quand on parle des coûts de serveur élevés pour exécuter des modèles d'IA.
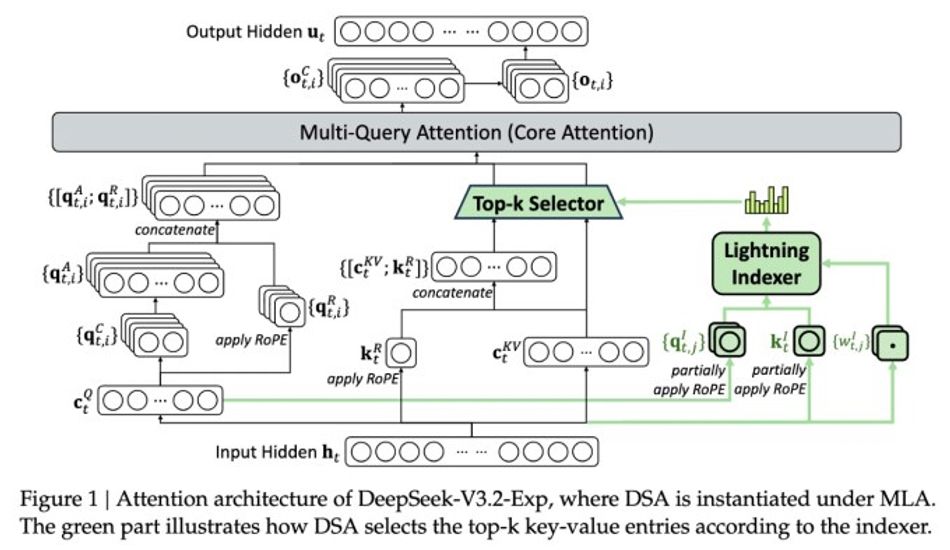
La vraie magie derrière ce modèle est quelque chose qu'ils appellent DeepSeek Sparse Attention. Maintenant, je ne vais pas vous ennuyer avec tous les détails techniques, mais l'idée principale est qu'il est conçu pour prioriser les parties les plus importantes de la fenêtre de contexte. Pensez-y comme ça : imaginez lire un long livre, mais en vous concentrant uniquement sur les paragraphes clés qui font avancer l'histoire. C'est essentiellement ce que fait ce système, ce qui permet de gérer les contextes longs sans surcharger le serveur.
Ce qui est vraiment excitant, c'est l'économie de coûts potentielle. Les tests préliminaires de DeepSeek suggèrent qu'un simple appel d'API pourrait coûter jusqu'à la moitié du prix dans des situations de contexte long. C'est très important ! Bien sûr, nous aurons besoin de plus de tests pour confirmer ces affirmations, mais le fait que le modèle soit open source et disponible sur Hugging Face signifie que des chercheurs indépendants peuvent intervenir et expérimenter.
Il est intéressant de voir DeepSeek, une entreprise basée en Chine, continuer à repousser les limites de l'efficacité de l'IA. Bien que leur précédent modèle R1 n'ait pas exactement déclenché une révolution, cette nouvelle approche d'attention clairsemée pourrait offrir des informations précieuses pour maîtriser les coûts d'inférence. Et, soyons honnêtes, c'est quelque chose qui profite à tout le monde dans le domaine de l'IA.
1 Image de DeepSeek V3.2-exp:
Source: TechCrunch